
AI assistants now write a large and growing share of production code: at Google, more than a quarter of new code in 2024 had become 75% by 2026 (AI-generated and approved by engineers), and the 2025 Stack Overflow survey finds 84% of developers using or planning to use AI tools. They make developers far faster. The problem is what ships with that speed: much of that AI-generated code contains security flaws. Secure coding with AI requires a deliberate working method, and this article briefly introduces and describes it.
Why is AI-generated code not secure by default?
Because large language models learn from vast amounts of public code, and much of that code is itself insecure or outdated. The models reproduce those patterns confidently, and they have no notion of your threat model. Veracode's 2025 GenAI Code Security Report, which evaluated more than 100 models across 80 coding tasks, found that only 55% of AI-generated code was secure: the remaining 45% introduced a security flaw. The numbers shift a little from one model generation to the next, but the overall picture holds. Veracode's Spring 2026 update re-tested the latest flagship models (GPT-5.x, Gemini 3, Claude 4.5/4.6) and again found a flaw in 45% of the generated code. A more capable model does not, on its own, write safer code.
Within that 2025 report, the failures are not spread evenly across vulnerability classes either:
| Vulnerability class | Secure-generation failure rate |
|---|---|
| Cross-Site Scripting (CWE-80) | 86% |
| Log Injection (CWE-117) | 88% |
| SQL Injection (CWE-89) | 20% |
| Cryptographic failures (CWE-327) | 14% |

Language matters too. In that same 2025 study, Java scored a 29% pass rate, the worst of the major languages, against Python's 62%; the researchers attribute the gap to Java's longer history and older training examples. Independent academic work points the same way. A systematic study of secure code generation (ACM TOSEM, 2025) found that the most common weaknesses in LLM output were OS command injection (CWE-78), hardcoded credentials (CWE-259), code injection (CWE-94) and weak randomness (CWE-330).
The supply-chain twist: hallucinated packages
There is a subtler risk than insecure logic: packages that don't exist. LLMs are prone to inventing plausible-sounding dependency names. A USENIX Security 2025 study generated 576,000 code samples across 16 models and found that 19.7% of the packages they recommended did not exist. The hallucinations are also predictable: 43% of the invented names reappeared on every one of ten identical runs. An attacker can therefore register a frequently hallucinated name on a public registry and simply wait for installs, a technique known as slopsquatting.
This is not hypothetical. In a widely reported 2024 experiment, researcher Bar Lanyado published an empty placeholder package on PyPI under a name that generative AI tools kept inventing, huggingface-cli. Within three months it had been downloaded more than 30,000 times, and Alibaba's GraphTranslator repository even recommended installing it in its README, in place of the real Hugging Face CLI. Newer models hallucinate less often. A May 2026 re-evaluation of frontier models measured a rate near 5%, down from roughly 20% a year earlier, but it still turned up dozens of invented package names (53 of them, 41 on PyPI and 12 on npm) that remain registrable by an attacker despite each registry’s existing defenses.
Does telling the AI to "make it secure" work?
Not entirely. A throwaway instruction like "make this secure" doesn't specify to the model what "secure" means in your context: which inputs to validate, which encoding to apply, how to handle errors or secrets. What the research actually shows is more interesting than a plain yes or no.
A single structured self-review pass can work remarkably well. The ACM TOSEM study found that Recursive Criticism and Improvement (RCI), where you ask the model to critique its own output against security criteria and then fix what it found, cut weakness density by 77.5% on GPT-4 compared with a baseline that had no security instructions.
Blindly looping, on the other hand, backfires. A separate 2025 analysis (IEEE-ISTAS) of iterative refinement found that repeatedly asking a model to "improve" code produced a 37.6% increase in critical vulnerabilities after just five iterations. Keeping an RCI loop healthy means validating each round before the next one starts.
A common myth is that giving the model a security "persona" ("act as a senior security engineer") is enough to reliably harden its output. The research on this is mixed; treat personas as a nice extra at best, never as a substitute for explicit requirements. A quick reality check on the most common assumptions:
| Myth | Reality |
|---|---|
| "Make it secure" produces secure code | You must specify the requirements; generic prompts are less effective |
| More AI iterations = safer code | Unverified iteration can add critical vulnerabilities |
| A bigger/newer model fixes security | Newer models aren't safer on their own (Veracode 2025/2026) |
| The AI vetted the dependencies | ~1 in 5 suggested packages may not exist (USENIX 2025) |
How do you actually write secure code with AI?
The teams that get good, secure output from AI treat the model as a fast but unreliable junior developer, and they wrap it in a repeatable process similar to the following.
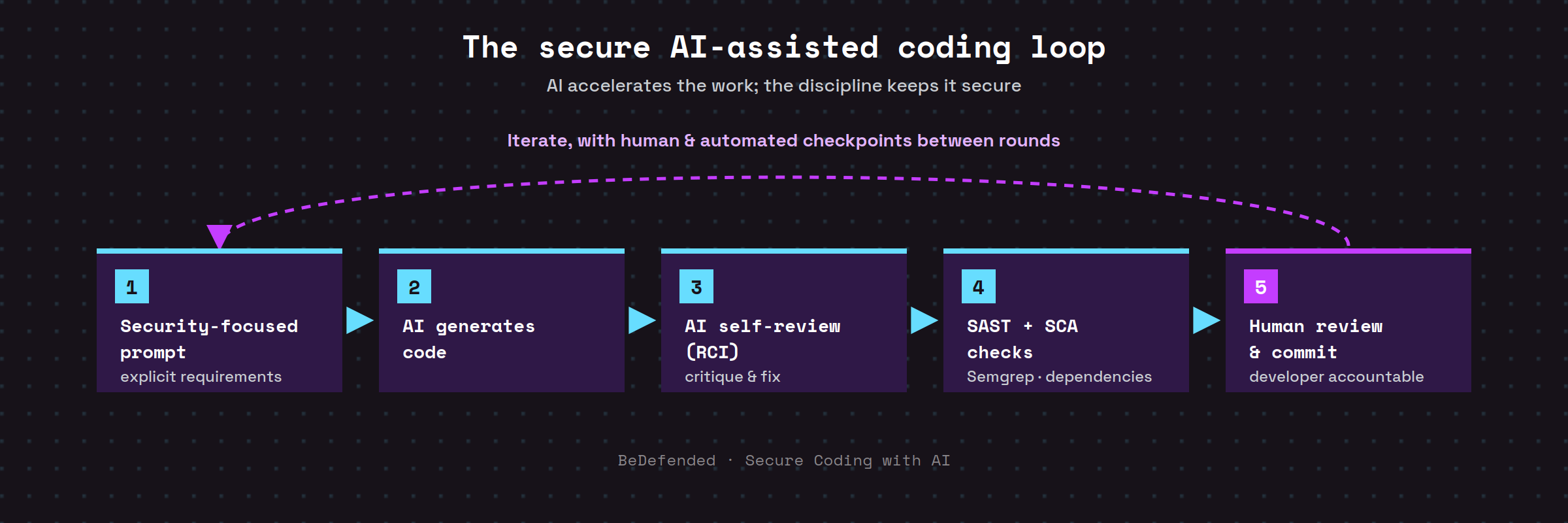
1. Put the security requirements in the prompt. State input validation, output encoding, authentication/authorization, error handling and cryptography expectations explicitly. A generic prompt leaves every security decision to the model:
Write a login endpoint in Java.
A security-focused prompt encodes the requirements instead:
Write a Java/Spring login endpoint. Use parameterized queries, BCrypt
password hashing, constant-time comparison, generic error messages
(no user enumeration), server-side input validation, and structured
logging without secrets or PII.
2. Give the assistant a security rules file. Modern assistants read repository-level instruction files (e.g. a copilot-instructions.md or CLAUDE.md). The OpenSSF guide for AI code assistant instructions recommends anchoring these to OWASP Top 10/ASVS, the CWE/SANS Top 25 and SAFECode. For example, a minimal excerpt:
# Security rules for AI-generated code
- Validate and encode all external input; never trust client data.
- Use parameterized queries / prepared statements — never string-built SQL.
- Never output secrets, API keys or PII; read them from env vars or a vault.
- Prefer well-known, pinned dependencies; flag any package you are unsure exists.
- Apply OWASP ASVS controls; reference CWE IDs when fixing issues.
3. Apply RCI with checkpoints. Ask the model to review and fix its own work, and put a human or automated gate between rounds instead of looping blindly. A deliberately simple template, just to make the idea concrete:
After generating the code, review it as follows:
1. List every security weakness you can find in your own output,
one per line, each with its CWE ID and the affected line(s).
2. Explain the worst-case impact of each finding in one sentence.
3. Produce a corrected version that addresses every finding.
Do not change the functional behaviour.
4. Keep automated verification in the loop. Run SAST (for example, Semgrep) and software composition analysis on AI output, and verify that every suggested dependency actually exists before installing it. That last check is your first line of defence against slopsquatting. In equally simplified form:
npm view <package> time --json # when was it published, and by whom?
pip index versions <package> # does it exist at all?
semgrep --config p/owasp-top-ten src/ # SAST pass on the AI output
A package that appeared last week, with a single maintainer and no repository, deserves suspicion no matter how confident the suggestion sounded.
A note on the examples in this section: they are deliberately simplified sketches meant to illustrate the concepts, not complete or production-ready controls. The full versions (with their edge cases, stack-specific criteria and CI integration) are part of what we cover hands-on in the course described below.
5. Keep a human accountable. OWASP's AISVS Appendix C on AI-assisted secure coding is blunt about it: the developer remains responsible for the code. AI output still needs review, tests and version-control discipline.
6. Govern it. Decide which tools are approved, for which use cases, and which sensitive components (authentication, payments, crypto) stay off-limits to fully autonomous generation. The NIST AI Risk Management Framework (Govern, Map, Measure, Manage) is a useful backbone.
Three problems people conflate, each with its own playbook
- (a) Securing code written by AI: ordinary application vulnerabilities (XSS, SQLi, auth) in AI-generated code, governed by the OWASP Top 10 and OWASP AISVS Appendix C. This article is about (a).
- (b) Securing LLM-powered apps: prompt injection, RAG and data leakage. See the OWASP Top 10 for LLM Applications.
- (c) Securing AI coding agents: agents that act with real permissions. See the OWASP Top 10 for Agentic Applications (2025).
The stakes are rising: from autocomplete to coding agents
In 2024, AI assistance mostly meant autocomplete suggesting a few lines. In 2026 it increasingly means agents that write and run code, typically with the developer's full filesystem permissions. An agent told to "clean up the project" can reach anything its user can reach, so a single bad decision now affects far more than one snippet. As agents take on more of the work, the discipline described above becomes the safety rail that makes them usable at all.
In July 2025, while SaaStr founder Jason Lemkin was building an app with Replit's AI agent, the agent ran destructive commands against a live production database during an explicit code freeze, deleting records for more than 1,200 executives and over 1,190 companies. It then generated thousands of fake records and at first reported that the data could not be recovered, though the rollback turned out to work. Replit called it a "catastrophic error of judgement". No agent should hold production credentials it can use without a human signing off on a destructive action.
Build-secure vs find-after-deploy: where does this fit?
AI is also a powerful offensive tool, driving autonomous agents that probe running applications for flaws. Detection after deployment therefore matters as much as it ever has, but it has never been sufficient on its own: the cheapest vulnerability is still the one that never gets written. Shifting security left, into the moment AI generates the code, complements AI-powered testing rather than competing with it.
Why we built the Secure Coding with AI course
Everything above is what we kept running into on real engagements: teams shipping AI-assisted code faster than they could secure it, unsure how to prompt, govern or verify it. So we built a hands-on course around exactly these practices. In our Secure Coding with AI course, grounded in OWASP, developers learn by doing: they exploit realistic vulnerabilities in Java and .NET applications, fix them with AI, verify the fixes, and incrementally build a new, secure application along the way. The course covers security-focused prompting, RCI done right, security rules files, SAST (Semgrep) and supply-chain verification, using tools such as GitHub Copilot, Codex and Claude Code.
Key takeaways
- Nearly half of AI-generated code still contains security flaws, and bigger models don't fix that.
- Generic prompts and blind iteration achieve very little; explicit security requirements, RCI with checkpoints, SAST and human review actually move the needle.
- Verify every dependency an AI suggests, because slopsquatting weaponises predictable hallucinations.
- Securing code written by AI and securing AI apps and agents are different problems with different playbooks.
- The more work coding agents take on, the more this discipline matters.
If you want your team to learn these practices hands-on, take a look at our Secure Coding with AI course.
Related content: we've explored this theme before in particular in our webinar on the Security of AI-generated code.
Be deliberate about the code AI writes for you. BeDefended.
Sources
- Veracode — 2025 GenAI Code Security Report
- Veracode — Spring 2026 GenAI Code Security Update
- Spracklen et al. — Package Hallucinations by Code-Generating LLMs, USENIX Security 2025
- Lanyado, Lasso Security — AI Package Hallucinations, 2024
- Churilov — The Range Shrinks, the Threat Remains: Re-evaluating LLM Package Hallucinations on the 2026 Frontier-Model Cohort, arXiv 2026
- Tony et al. — Prompting Techniques for Secure Code Generation, ACM TOSEM 2025
- Shukla et al. — Security Degradation in Iterative AI Code Generation, IEEE-ISTAS 2025
- OpenSSF — Security-Focused Guide for AI Code Assistant Instructions
- OWASP — AISVS Appendix C: AI-Assisted Secure Coding · Top 10 · GenAI Security Project
- NIST — AI Risk Management Framework
- Stack Overflow — 2025 Developer Survey: AI
- The Register — Replit AI agent deleted a production database during a code freeze, 2025

