
The most important thing while doing a Penetration Test is understanding the application you’re testing, including any obfuscation present.
If you don’t take the time to understand the app more deeply, you might miss possible vulnerabilities that are specific to this application or environment. It’s important to go beyond the most common issues and find something more hidden – and you can’t do that without understanding the code.
We all try to write secure code, but sometimes it might not be enough. Writing secure code, in fact, doesn’t protect the code itself. Why would we want that? Because there can be intellectual properties, business logic or secrets (however it’s strongly recommended that secrets aren’t hard-coded, especially client-side, so you should avoid it) that you might want to protect: the answer for this is obfuscation.
What is obfuscation?
Obfuscation means scrambling and changing the code in such a way that it becomes more difficult for humans to understand. Reading obfuscated code takes a lot of time because variables and functions are renamed and logic is often unclear at first.
Example:
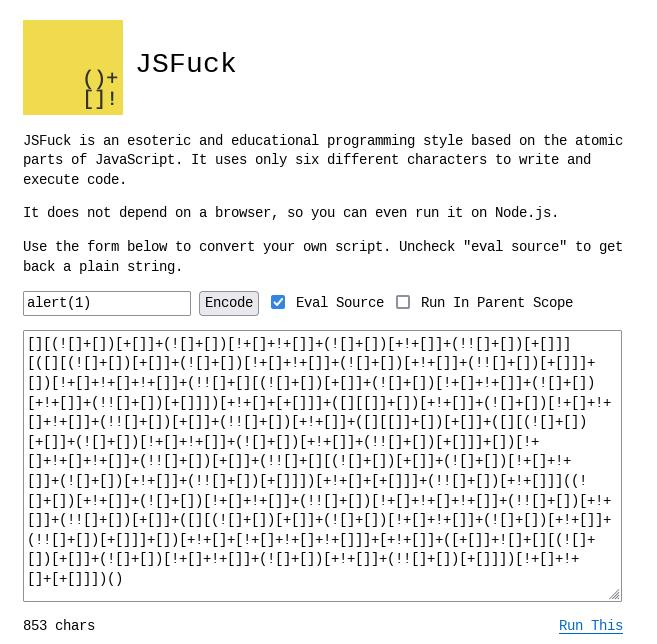
In the preceding image, alert(1) becomes a series of 853 characters that are unintelligible without knowing the logic behind it.
There are two types of programming languages when it comes to the output produced: compiled and interpreted. In case of the former, before the code is executed it gets transformed to machine code, which, as the name implies, it’s not easily human-readable. Interpreted languages, for example JavaScript, remain unchanged, so they are executed the same way as they are written. This is the type of programming language that needs obfuscation the most.
JavaScript is actually a language that used to be exclusive for the browsers, yet nowadays, it can also be found outside web applications, taking the form of an Android/iOS application or a Windows/macOS/Linux one. It’s all thanks to frameworks like React Native. They take your code-base and generate code that can be used on any platform. In fact, cross-platform programming became so popular that JavaScript is pretty much everywhere nowadays.
In the case of more recent versions of React Native, there is a difference in that the JavaScript code does get compiled when using the default options. However, there might be reasons we choose not to do it, for example a bug in RN that would have a performance or compatibility issue in our application. This leads to having the code being easily readable and understood.
What tools are available for JavaScript obfuscation?
There are many solutions you can use to obfuscate JavaScript code with, both open source and commercial ones. We have researched some of them in order to test how difficult it would be for an attacker to reverse them.
The one free and open source solution you might’ve already come across is probably “obfuscator.io“, which is the one we’ll be starting from.
The tools we used to carry out the deobfuscations are:
In fact, our goal was to do this analysis with tools that anyone can download and use for free. Tools which require little or no knowledge of manual reverse engineering techniques.
Obfuscator.io
The source code we are obfuscating is:
const xhr = new XMLHttpRequest();
xhr.open('GET', 'https://example.com');
xhr.onload = () => {
if (xhr.status === 200) {
const response = xhr.responseText;
const element = document.createElement('div');
element.innerHTML = response;
document.body.appendChild(element);
} else {
console.error('Request failed. Returned status of ' + xhr.status);
}
};
xhr.send();but after using “obfuscator.io” with default settings, it will look like this:
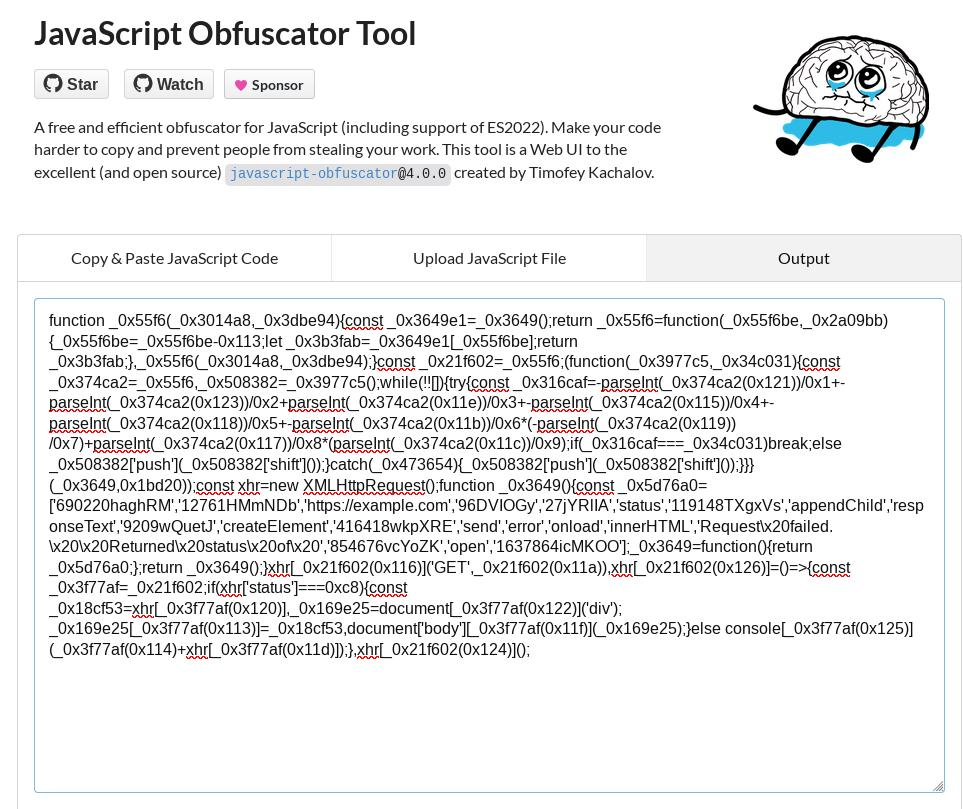
Looks pretty good to the human eye as it’s definitely hard to understand and follow through at a glance. Is it enough though?
Let’s check what we can achieve by trying to deobfuscate it with a dedicated tool, in this case with “restringer”:
function _0x55f6(_0x3014a8, _0x3dbe94) {
const _0x3649e1 = [
'innerHTML',
'Request failed. Returned status of ',
'854676vcYoZK',
'open',
'1637864icMKOO',
'690220haghRM',
'12761HMmNDb',
'https://example.com',
'96DVIOGy',
'27jYRlIA',
'status',
'119148TXgxVs',
'appendChild',
'responseText',
'9209wQuetJ',
'createElement',
'416418wkpXRE',
'send',
'error',
'onload'
];
_0x55f6 = function (_0x55f6be, _0x2a09bb) {
_0x55f6be = _0x55f6be - 275;
let _0x3b3fab = _0x3649e1[_0x55f6be];
return _0x3649e1[_0x55f6be];
};
return _0x55f6(_0x3014a8, _0x3dbe94);
}
const xhr = new XMLHttpRequest();
function _0x3649() {
return [
'innerHTML',
'Request failed. Returned status of ',
'854676vcYoZK',
'open',
'1637864icMKOO',
'690220haghRM',
'12761HMmNDb',
'https://example.com',
'96DVIOGy',
'27jYRlIA',
'status',
'119148TXgxVs',
'appendChild',
'responseText',
'9209wQuetJ',
'createElement',
'416418wkpXRE',
'send',
'error',
'onload'
];
}
xhr.open('GET', 'https://example.com');
xhr.onload = () => {
if (xhr.status === 200) {
const _0x18cf53 = xhr.responseText;
const _0x169e25 = document.createElement('div');
_0x169e25.innerHTML = _0x18cf53;
document.body.appendChild(_0x169e25);
} else
console.error('Request failed. Returned status of ' + xhr.status);
};
xhr.send();As you can notice, there is extra code that remained after the deobfuscation. However, if you go lower you can find code that greatly resembles the original one.
After removing the dead code, this is what we get:
xhr.open('GET', 'https://example.com');
xhr.onload = () => {
if (xhr.status === 200) {
const _0x18cf53 = xhr.responseText;
const _0x169e25 = document.createElement('div');
_0x169e25.innerHTML = _0x18cf53;
document.body.appendChild(_0x169e25);
} else
console.error('Request failed. Returned status of ' + xhr.status);
};
xhr.send();This one matches our original code, apart from the variable names which are not restorable.
The second tool, “Webcrack”, seems to resolve the code better than “Restringer”. The result we get is already cleaned from the dead code:
const xhr = new XMLHttpRequest();
xhr.open("GET", "https://example.com");
xhr.onload = () => {
if (xhr.status === 200) {
const _0x18cf53 = xhr.responseText;
const _0x169e25 = document.createElement("div");
_0x169e25.innerHTML = _0x18cf53;
document.body.appendChild(_0x169e25);
} else {
console.error("Request failed. Returned status of " + xhr.status);
}
};
xhr.send();“Synchrony” gives very similar results to “Webcrack”, and the result code highly matches the original one.
const xhr = new XMLHttpRequest()
xhr.open('GET', 'https://example.com')
xhr.onload = () => {
if (xhr.status === 200) {
const _0x18cf53 = xhr.responseText,
_0x169e25 = document.createElement('div')
_0x169e25.innerHTML = _0x18cf53
document.body.appendChild(_0x169e25)
} else {
console.error('Request failed. Returned status of ' + xhr.status)
}
}
xhr.send()Ok. These are the results with the Default preset, which might not cover the needs for a more advanced protection.
“Obfuscation.io” part 2 – when higher doesn’t mean better
Now let’s try with the highest preset. We also enabled the custom option of “Rename Globals” and “Rename Properties” to further increase the level of the obfuscation.
The obfuscated code results in 1285 lines of beautified code.
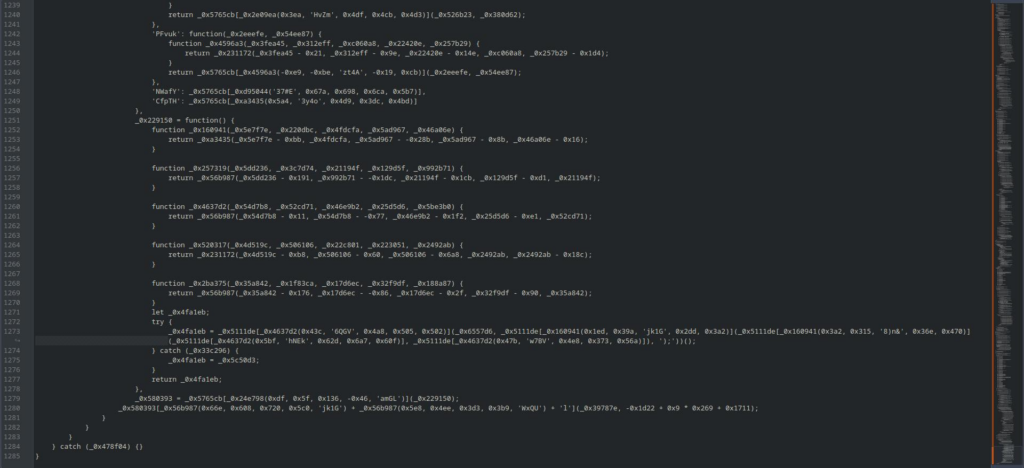
Compared to the Default preset where they were inserted into an array exactly as they were, strings are now split and noise is added thanks to many other words present:
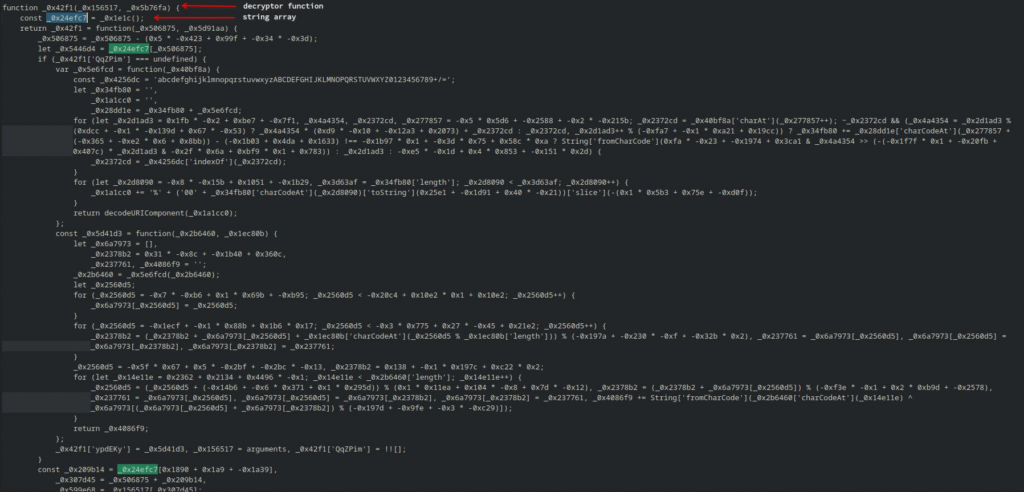
The “decryptor” function for the preceding array is also seemingly more complex, as there are more transformation happening to the strings:

However, passing the code through “Webcrack” we get the following:
const _0x4a7569 = new XMLHttpRequest();
_0x4a7569.open("GET", "https://example.com");
_0x4a7569.onload = () => {
if (_0x4a7569.status === 200) {
const _0xae2aec = _0x4a7569.responseText;
const _0x25edc4 = document.createElement("div");
_0x25edc4.innerHTML = _0xae2aec;
document.body.appendChild(_0x25edc4);
} else {
console.error("Request failed. Returned status of " + _0x4a7569.status);
}
};
_0x4a7569.send();which resembles our original source code without any protection, such as anti-tampering or anti-debugging, any obfuscation or any dead-code. In fact, once a code is fully deobfuscated, it does not matter what protections does it use as those checks can be then removed.
As we noticed, different deobfuscators lead to slightly different results. All of them, though, produce code that highly resembles the source code used with “obfuscator.io”. In fact, as an open-source solution, every transformation that might rely on can be studied and implemented in reverse to restore almost all the original source code.
Even if it can’t be used in critical apps “obfuscator.io” might still help with prevention from less technical attackers.
Now onto the commercial obfuscators.
Commercial obfuscator no.1
With the first commercial obfuscator we’ve analysed, we’ve noticed the results to be very similar to the obfuscated code of “obfuscator.io”.
Side by side comparison of the beautified obfuscation:
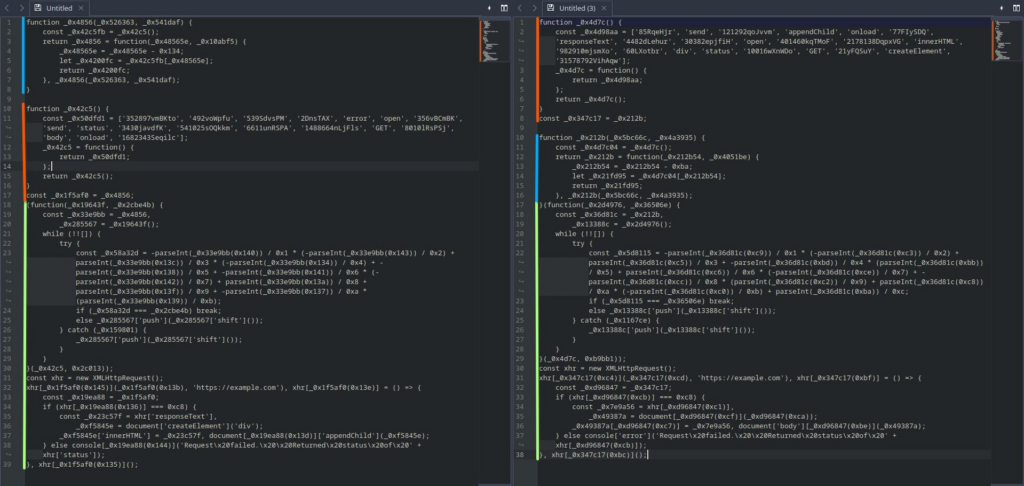
Left: Commercial tool no.1 – Right: “Obfuscator.io” with default preset
Actually, once beautified it’s possible to see that strings don’t pass through any special transformation for obfuscation. This is because the Default preset is used, which usually offers a lower protection for the benefit of performance and compatibility. Also, since there weren’t any transformation that are considered more advanced, like control flow flattening, it’s easy to spot our code in the final result. This however might not be as simple on larger code-bases.
It’s important to note that even when variable names are scrambled, the non obfuscated strings that remain as is are still a quite strong indicator of what is the purpose of the function.
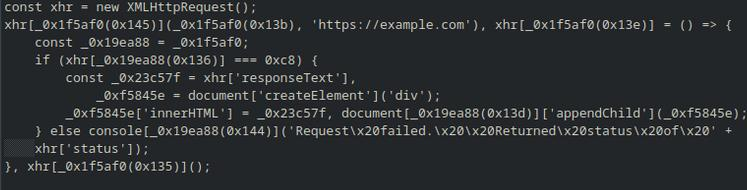
Since commercial tool no.1 in its default seems to use techniques similar to the ones in “obfuscator.io”, the above deobfuscators give similar results:
const xhr = new XMLHttpRequest();
xhr.open("GET", "https://example.com");
xhr.onload = () => {
if (xhr.status === 200) {
const _0x4f32fa = xhr.responseText;
const _0x4af738 = document.createElement("div");
_0x4af738.innerHTML = _0x4f32fa;
document.body.appendChild(_0x4af738);
} else {
console.error("Request failed. Returned status of " + xhr.status);
}
};
xhr.send();No other presets were available to choose from.
Commercial obfuscator no.2
One of the very first things we notice when testing commercial tool no.2 is that it doesn’t follow the same approaches as “obfuscator.io” or commercial tool no.1.
Strings, for example, didn’t appear in the usual string array. They were found to go through a more advanced technique that also encrypts them.
For the analysis of this tool we used a custom script that combines different deobfuscators in order to carry on a better result, the same script that we wrote for our Penetration Testing activities. We couldn’t, though, reverse the code obfuscated with Commercial tool no.2 using the resources we currently had implemented. The resulting code would still need to go through considerable manual analysis, thus passing our test.
Conclusion
There is no one true solution to irreversibly obfuscating your code. As with any client-side code, there are advanced techniques and a lot of time that can you can invest to undo such code. Just as it’s an endless game of cat and mouse between CAPTCHA solvers and CAPTCHA protections against online bots, no method is foolproof to an attacker with time and resources. That’s why you shouldn’t hide secrets or other highly sensitive information, such as intellectual property, in the code that runs on the user’s device.
Nonetheless, as this analysis showed, just because a tool is commercial does not mean it’s trustworthy. For this reason it’s always important, before buying any solution, to perform an in-depth assessment. Possibly, reach out to a specialized company that can help with such analysis and recommend the right tool for your needs.
Be aware of client-side obfuscation solutions. BeDefended.
Thanks for reading.

